
0. イントロダクション
知能、それは人類最大の武器であり特権であり謎でした。目まぐるしい技術発展の最高到達点として人類とは異なる知能が今まさに生み出されようとしています。そのインパクトは想像に難くないでしょう。
市場は既にAIをめぐる巨大なマネーゲームを始めています。その背景にはスケーリング則があります。データと計算リソースとパラメータを適切に増やしていけばその分だけ性能も向上するというものです。大規模な学習により訓練されたChatGPTの公開は世界に衝撃を走らせました。それ以降巨大な資本を投じて先端モデルの学習が行われ、競争は過熱しています。しかし、立ち止まって考えてみると人間は現在のAIよりも遥かに少ないデータ量で効率的な学習を行っています。つまり、スケーリングではない、アーキテクチャ的な革新によって人工知能が大きく発展する余地が残されているのです。
キーワードとなるのは「対称性」です。データの裏にある対称性を活かすことで性能の向上や効率的な学習を見込めます。本記事では「対称性」を指導原理としてアーキテクチャを設計する考え方について解説をします。1章ではなぜ対称性が重要なのか、2章では幾何的深層学習についてその考え方と実証例を解説します。幾何的深層学習は対称性をアーキテクチャに組み込む方向性を明確に打ち出したものです。そして、3章ではより柔軟に対称性を記述するための「圏論的機械学習」というアイディアをご紹介します。
1. なぜ対称性が重要なのか
対称性はなぜ重要なのでしょうか。それは、
現実世界の背後に多様な対称性が存在していてそれを活用することで良い予測が可能になる
からです。まず良い予測が可能になるというところですがこれはby definitionです。ここで対称性という言葉の定義をきちんと確認しておきましょう。対称性とは「変換に対する不変性」のことです。ここでは不変性だけでなく同変性も対称性と呼ぶことにします。同変性は入力の変化に対する変換後の出力が整合的に変化することです。これらの不変性や同変性は2.2で解説するように群論で記述することが多いです。さて、時間経過に伴う変換に対して不変あるいは同変な構造がもし存在すればそれを活用することで良い予測が可能になると考えられます。これは、「予測のために対称性が活用できる」と対称性の定義から言い換えられます。
次に現実世界の背後に多様な対称性が存在していることについてですが、これは非常に非自明な主張です。突き詰めて考えれば存在論的な哲学の問題になります。しかし不思議なことに素朴には現実世界に様々な対称性が存在していると考えられます。例えば、人間や動物の身体は左右対称になっています。結晶格子、DNAの螺旋構造は一定程度ずらしてもその形を保つという並進対称性があります。分子はその幾何形状を保つので点群対称性があります。物理学においては保存則は対称性そのものですし、座標変換によって不変というゲージ対称性などもあります。さらに統計学的視点からは確率分布が対称性として現れます。例えばコインを投げるのと靴飛ばしをするのとは違う行為なはずなのにその裏にはベルヌーイ分布が現れるのです。このように世界には様々な対称性が潜んでおり色々なかたちで記述されています。
機械学習や深層学習の文脈では予測のために仮定する現実世界に対するバイアスを帰納バイアスと言います。これは重要な概念なので説明をします。機械学習は訓練データを元に未知の予測をするモデルを組むものです。学習においてはデータは高々有限なため、モデルのパラメータが十分にあれば訓練データを完全に再現できます。しかし、重要なのは未知の予測をできるという汎化性能です。訓練データを完全に再現できるとしてもそのようなモデルは無数に存在するのでその中で汎化を達成するものを選ぶことが重要になります。ここでモデルを選択するために仮定する基準が帰納バイアスとして必要になります。現実を反映するバイアスを帰納して実装することでモデルの汎化を実現させます。
帰納バイアスの古典的な指標としては滑らかさや単純さがあります。入力の変化に対して出力が滑らかに変わる、モデルが単純に表現されるというのは自然な仮定ですね。しかし、従来の「滑らかさ」や「単純さ」という帰納バイアスには限界があります。低次元では、関数が滑らかであるという仮定だけでも、観測されていない点の値を近くの観測点から推定できます。しかし深層学習のように高次元なデータを扱う場合は、空間そのものが爆発的に広がるため、各点の近くに十分なデータを集めるには次元に対して指数的なサンプル数が必要になります。これを次元の呪いと言います。したがって、高次元データに対しては、単に「滑らかな関数を選ぶ」というだけでは不十分です。必要なのは、データの背後にあるより強い構造を捉える帰納バイアスです。ここで対称性を活用しようという発想が生まれます。先ほども触れたとおりそれは現実世界に様々なかたちで潜んでいるからです。
したがって、話をまとめると「より良い予測のために世界に存在する対称性を帰納バイアスとして活用できる」と言えます。これが機械学習や深層学習において対称性が重要である理由です。
次の章では対称性をアーキテクチャに組み込むための考え方である幾何的深層学習について解説をします。
2. 幾何的深層学習とは
2.1 幾何的深層学習というposition
幾何的深層学習とは特定のアーキテクチャ構造を示すわけではなく、少し私の解釈が含まれるかもしれませんが、実はpositionのことです。つまり、幾何的深層学習に取り組むとは幾何的な対称性を指導原理としてアーキテクチャを設計する立場を取ることです。そして本当に重要な考え方は実は1章で説明した通りです。繰り返すと「対称性は構造を捉える帰納バイアスとして活用できる」ということです。
幾何的深層学習の興りを見てましょう。Bronsteinらの2017年サーベイ Geometric Deep Learning: Going beyond Euclidean data は、CNNの成功を、画像データの背後にあるユークリッド的な格子構造と平行移動対称性をアーキテクチャに組み込んだ結果として捉え直し、その発想を非ユークリッドデータへ拡張するものとして幾何的深層学習を位置づけました。さらに2021年の Bronstein, Bruna, Cohen, Veličković による Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges では、この立場がより体系的に整理されました。この論文は、CNN, GNN, RNN, Transformerなど深層学習におけるさまざまなアーキテクチャを、データの背後にある幾何構造と対称性から統一的に理解することを掲げました。著者らは、画像、集合、グラフ、多様体、物理系などのデータを、それぞれ異なる空間上の信号として捉え、その空間にどのような変換や対称性があるかに応じて、適切なニューラルネットワークの形が決まると考えました。このようにアーキテクチャをおもに幾何的な対称性から位置づけた整理がなされ、次のアーキテクチャを設計するために対称性を活用することが提唱されました。このように対称性を帰納バイアスとして使おうというのが幾何的深層学習のソウルとなっています。
2.2 幾何的深層学習の記述
群論はある種の対称性を記述します。幾何的深層学習においてはまずこの群論を用いて対称性をアーキテクチャに組み込もうという流れがありました。ここでは特に同変性に絞ってその記述の仕方を解説します。
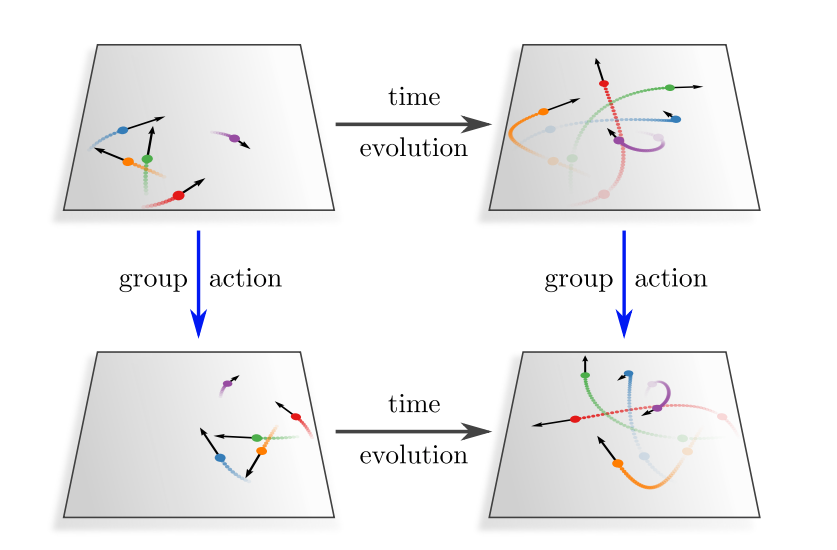
図1. 群作用による座標変換による時間発展の様子は同変である。
同変性とは入力の変化に対する変換後の出力が整合的に変化することでした。例えば、時間発展そのものを変換とみなします。このとき座標変換も同時に考えると時間発展は座標変換に対して同変であると言えます。これは座標変換をしてから時間発展するのと時間発展してから座標変換をするのが「可換」になっているからです。この可換性が入力の変化に対する変換後の出力が整合的に変化するということを簡潔に表します。したがって、式においても同変性とは を対称性を記述する群、 を が作用する空間、 を 上の変換とすると、
が成り立つ、と書けます。
このように記述される同変性がアーキテクチャにどのように組み込まれるのでしょうか。それは をモデルの重み行列と見たときにこの可換性の条件を に対する制約だと考えることで実現されます。より具体的には、対称性を仮定しそれを群作用で記述すると は所与のものになるのでこの条件は の方程式と考えられます。これを解くと のパラメータは完全には決定しませんが、例えば対角成分が全て等しいというように、 のパラメータに関する具体的な条件が得られ、行列のかたちが制限されます。この制限は重みを共有を表していると見ることができ、 を並進対称性を表す群とすれば畳み込みの定式化と一致します。したがって、畳み込みニューラルネットワークが対称性を織り込んだものであり、その一般化が同変性を織り込むニューラルネットワークであることが理解できます。
2.3 実証例
AlphaFold2(2020年のCASP14で圧勝、2021年Nature)は、残基をSE(3)同変な剛体フレームとして扱う構造モジュールを核に、タンパク質構造予測をほぼ実験精度まで引き上げ、2024年のノーベル化学賞につながりました。そのほかにも実証的に成功したアーキテクチャは多くあります。
| 領域 | 幾何構造 | 成功しているモデル例 |
|---|---|---|
| 天気予報 | 地球表面・大気グラフ | GraphCast |
| タンパク質 | 3D構造・距離・角度 | AlphaFold |
| 分子物性 | 3D原子グラフ・E(3)対称性 | EGNN, SE(3)-equivariant GNN |
| 球面データ | 球面・局所フレーム | Icosahedral CNN, Gauge Equivariant CNN |
| 医療・dMRI | 方向場・球面/射影空間 | steerable/gauge equivariant models |
| 物理 | ゲージ対称性・保存則 | Lattice Gauge Equivariant CNN |
3. 圏論的対称性へ
3.1 何が足りないのか
幾何的深層学習ではCNNが群論的対象性を組み込んだアーキテクチャであることが整理され、その方向性で拡張がなされています。しかし、群論的対称性だけでは足りないのです。例えば現実の対称性としては
- 犬、柴犬、横向きの柴犬など階層的な対称性
- ゲージ対称性などの局所的な対称性
- 画像の非可逆圧縮などの非可逆的な対称性
- 確率分布などの統計的対称性
などがあり挙げればキリがないでしょう。これらの対称性に対応する枠組みが必要になります。
3.2 圏同変ニューラルネットワーク
私たちは群では記述しきれない対称性を圏論によって記述しようという立場をとります。これがシン・機械学習=圏論的機械学習というポジションです。圏論的機械学習はまだ確立された手法はなくいくつか成果が出始めている萌芽の段階にあります。しかし、圏論は様々な対象、例えば直和、直積、テンソル積、局所化などを極限として統一的に記述できるため記述力の高い枠組みとして知られており、この方向性は非常に期待できるものと考えています。
一つのアイディアとして圏同変ニューラルネットワーク(CENN)を見てみましょう。CENNは[maruyama,2025]により提唱されました。圏、関手、自然変換のきちんとした定義はここでは述べませんが、これらの関係性は関手が圏の間の準同型であり自然変換が関手の間の準同型であると考えて良いです。アイディアのキーとなるのは自然変換が図式の「可換性」によって定義されることです。圏同変ニューラルネットワークは自然変換として定式化されます。
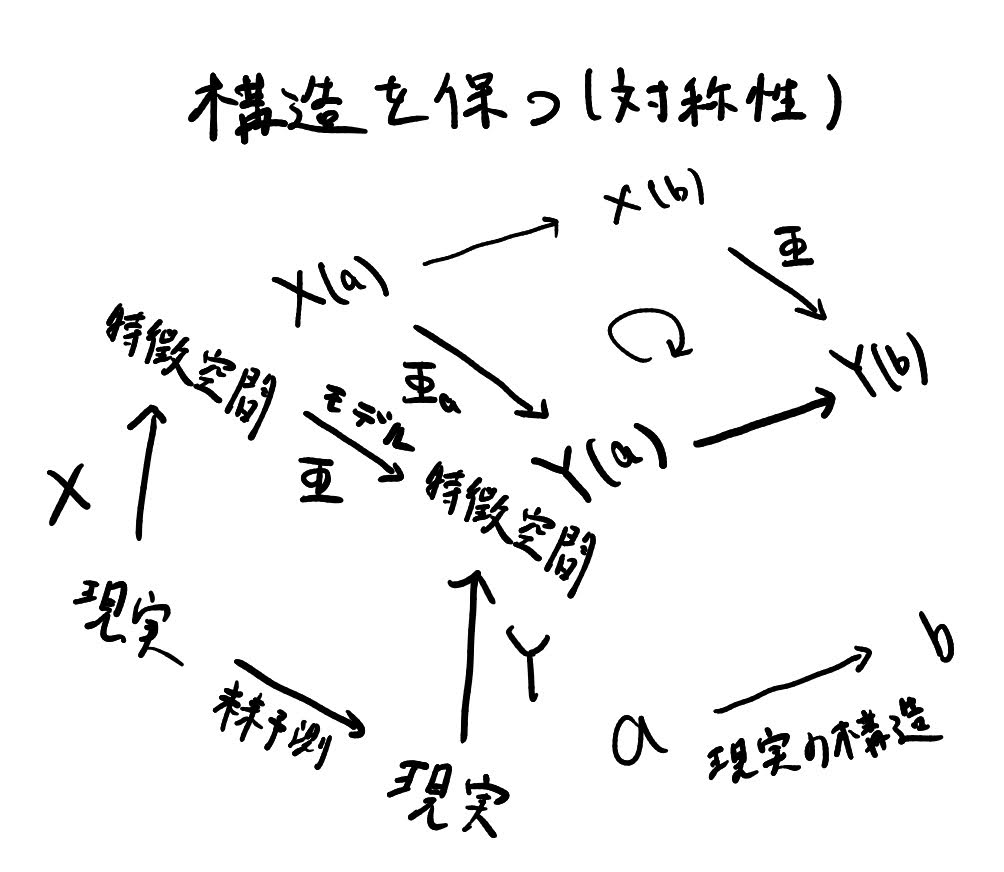
論文とは少し異なりますがそのアイディアを具体的に記述します。まず現実のデータを圏Cとして記述します。そしてXを現実を特徴空間にエンコードする関手、Yを現実を特徴空間にデコードする関手とします。関手とすることで特徴が圏Cの構造を保ちます。このとき、関手XとYの間の自然変換φとして機械学習モデルを定式化できます。φが自然変換であることは図のように特徴空間においてモデルφが可換である、つまり同変であることに他なりません。この自然変換の可換性を用いた同変性こそが私たちが圏論的対称性と呼ぶものです。
3.3 言語モデルへの応用とアイディア
圏論的機械学習は対称性を圏論的に記述しそれを帰納バイアスとしてアーキテクチャを設計する立場のことです。そのような方向性は先ほど紹介した考え方の他にもいくつかありますが、萌芽的な段階であり確立した手法はありません。私たちは特にこの考え方を言語モデルへと応用する研究に取り組んでいます。
一つのアイディアとして取り組んでいるのが、幾何代数(Clifford 代数)を用いた定式化です。文の意味は単語の組合せ、すなわち多重線形な合成から立ち上がりますが、この合成がもつ対称性と交代性を、幾何代数はひとつの代数構造の中で素直に書き下せます。具体的には、単語をベクトル(1 次)、その組合せをバイベクトルやより高次のマルチベクトルとして表すことで、語から句、節へと積み上がる言語の自己相似的な階層構造を、次数の違いとして自然に表現できます。さらに幾何積は対称な内積と交代なウェッジ積の和に分解されるため、順序が意味を変えない結合と順序が意味を変える結合の双方を、一つの演算の中で区別して扱えます。こうした代数構造をアーキテクチャに組み込めば、合成のもつ不変性・同変性をデータから学習し直す必要がなくなり、構造そのものが帰納バイアスとして働きます。これは画像における並進不変性(CNN)や集合における置換不変性と同じ発想を、言語の合成構造へ持ち込む試みといえます。幾何代数を用いた機械学習はこれまで物理現象や 3D 処理など幾何的データに限られてきましたが、高次元の幾何代数は言語モデリングにも強力な原理を与えうると考えられます。もっとも、言語のどの操作が対称でどれが交代に対応するのかという定式化そのものが本質的な課題であり、私たちはこの対応づけを足がかりに、圏論的機械学習の枠組みを言語モデルへと拡張することを目指しています。
さらに、予測符号化や自由エネルギー原理など神経科学分野の知見、記号創発システム論、ネオ・サイバネティクスなどの学際分野をさらに融合させた野心的な取り組みができればと考えています。
まとめ
本記事では「対称性」を指導原理としてアーキテクチャを設計するという考え方を一貫して追ってきました。スケーリングだけに頼らず、現実世界に潜む多様な対称性を帰納バイアスとして活用することで、より効率的で汎化性能の高い学習が可能になります。幾何的深層学習はこの発想を群論的対称性として明確に打ち出し、CNNからAlphaFoldに至るまで数々の実証的成功を生み出してきました。しかし群論では階層的・局所的・非可逆的・統計的な対称性を捉えきれず、そこで私たちはより記述力の高い圏論によって対称性を捉え直す「圏論的機械学習」を提唱します。圏同変ニューラルネットワークや幾何代数を用いた言語モデルへの応用を足がかりに、やがては神経科学や記号創発、ネオ・サイバネティクスとも融合した、知能そのものの新たな理解へと至る——そんな野心的な地平を私たちは目指しています。
参考文献
- Bronstein, M. M., Bruna, J., LeCun, Y., Szlam, A., & Vandergheynst, P. (2017). Geometric Deep Learning: Going beyond Euclidean Data. IEEE Signal Processing Magazine, 34(4), 18–42.
- Bronstein, M. M., Bruna, J., Cohen, T., & Veličković, P. (2021). Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges. arXiv:2104.13478.
- Maruyama, Y. (2025). Categorical Equivariant Deep Learning: Category-Equivariant Neural Networks and Universal Approximation Theorems. arXiv:2511.18417.
- Jumper, J. et al. (2021). Highly accurate protein structure prediction with AlphaFold. Nature, 596, 583–589.(AlphaFold2)
- Lam, R. et al. (2023). Learning skillful medium-range global weather forecasting. Science, 382, 1416–1421.(GraphCast)
- Satorras, V. G., Hoogeboom, E., & Welling, M. (2021). E(n) Equivariant Graph Neural Networks. ICML.(EGNN)
- Fuchs, F., Worrall, D., Fischer, V., & Welling, M. (2020). SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks. NeurIPS.(SE(3)-equivariant GNN)
- Cohen, T., Weiler, M., Kicanaoglu, B., & Welling, M. (2019). Gauge Equivariant Convolutional Networks and the Icosahedral CNN. ICML.(Icosahedral CNN / Gauge Equivariant CNN)
- Favoni, M., Ipp, A., Müller, D. I., & Schuh, D. (2022). Lattice Gauge Equivariant Convolutional Neural Networks. Physical Review Letters, 128, 032003.(Lattice Gauge Equivariant CNN)
- Cohen, T., & Welling, M. (2016). Group Equivariant Convolutional Networks. ICML.
- 前田晃弘・鳥居拓馬・大関洋平・日髙昇平 (2026). 構成性を実現する言語モデルの数理基盤——構成的汎化を導く表現論的逆問題としての学習. 『人工知能学会論文誌』41巻4号, AN40-A.
- Ruhe, D., Gupta, J. K., De Keninck, S., Welling, M., & Brandstetter, J. (2023). Geometric Clifford Algebra Networks. Proceedings of the 40th ICML, 202, 29306–29337.
- Brehmer, J., de Haan, P., Behrends, S., & Cohen, T. (2023). Geometric Algebra Transformer. NeurIPS. arXiv:2305.18415.


